
בניתי את הפונקציה ב2 שלבים, הראשון סטים שמכילים את כל המילים שבטקסט (מילון אחד למילים “נקיות” והשני מילון שמנקה) והבעיה שלי היא במילון השני, הוא עובד מצויין כמעט על כל המילים כמו שניתנו בהערת בדיקה, אבל ל2 מילים הוא לא מנקה לגמרי:
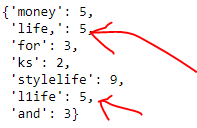
כמו שאתם יכולים לראות, במקרה אחד יש לי פסיק שלא נמחק ובמקרה השני את הספרה 1 שלא נמחקה.
ביססתי את הסט על הפעולה שאם התו הוא לא אות שיחליף אותו בכלום.
איזשהו שמץ למה שני התווים האלו לא נמחקים?
בדקתי גם ב- python tutor וגם שם קיבלתי את אותה התוצאה, מצד שני כשלקחתי את את הסטרינגים לבד וניקיתי אותם ידנית (replace לכל תו במידה והוא לא אות) הם כן התנקו כמו שצריך.
מקפיץ…
אם תרצו שאסביר על אילו פונקציות מובנות התבססתי בכתיבת הקוד אפרסם בתקווה שזה לא יחשוף לאחרים יותר מדי, אבל בינתיים אני תקוע וצריך את עזרתכם
נסה להריץ רק על שני המילים האלה ותראה למה זה לא עובד לך.
אם זה לא מנקה אותם זה כנראה לא יודע עליהם.
מצאתי את הבעיה אבל אני לא בטוח איך לפתור אותה,
הבעיה שלי היא שכיוון שהקוד צריך לרוץ כל פעם על כל אות ולבדוק אם היא אות אנגלית או לא, במילים שיש בהן יותר מתו אחד שהוא לא אות אנגלית אני מקבל תוצאה שמוחקת כל פעם תו אחד.
אני יכול לפתור את זה אם אני מריץ את הקוד פעמיים, אבל זה לא יכסה מצבים שיהיו בהם 3 אותיות שהן לא אנגלית והלאה.
הבעיה שלהבדיל מהכתיבה שאנחנו רגילים אליה שאני יכול להזיח את ההוספה של המילה “שלב אחד אחורה” (בעצם תחת ה- for word in text) ב- Comprehensions אין לי את האופציה הזאת אבל אני בכל זאת חייב להשתמש בתנאי מתחת לתנאי (למילה בטקט, לאות במילה).
אם ככה איך אני יכול לשנות את זה כדי שזה יעבור על כל האותיות ורק אז ישמור את המילה (כמו שאני יכול לעשות עם הדרך הראשונה)