
כן, ישנה חשיבות לסדר השורות 
אוקי, האם צריך לשמור על הסדר המקורי ופשוט ״לחבר״?
לסדר לפי משהו אחר?
שים לב שבדוגמה שלך סדר השורות של הקובץ הראשון מתהפך (ולכן השאלה)
לא ראיתי איפה בדוגמה סדר השורות מתהפך ^^
כן, מה שאמרת
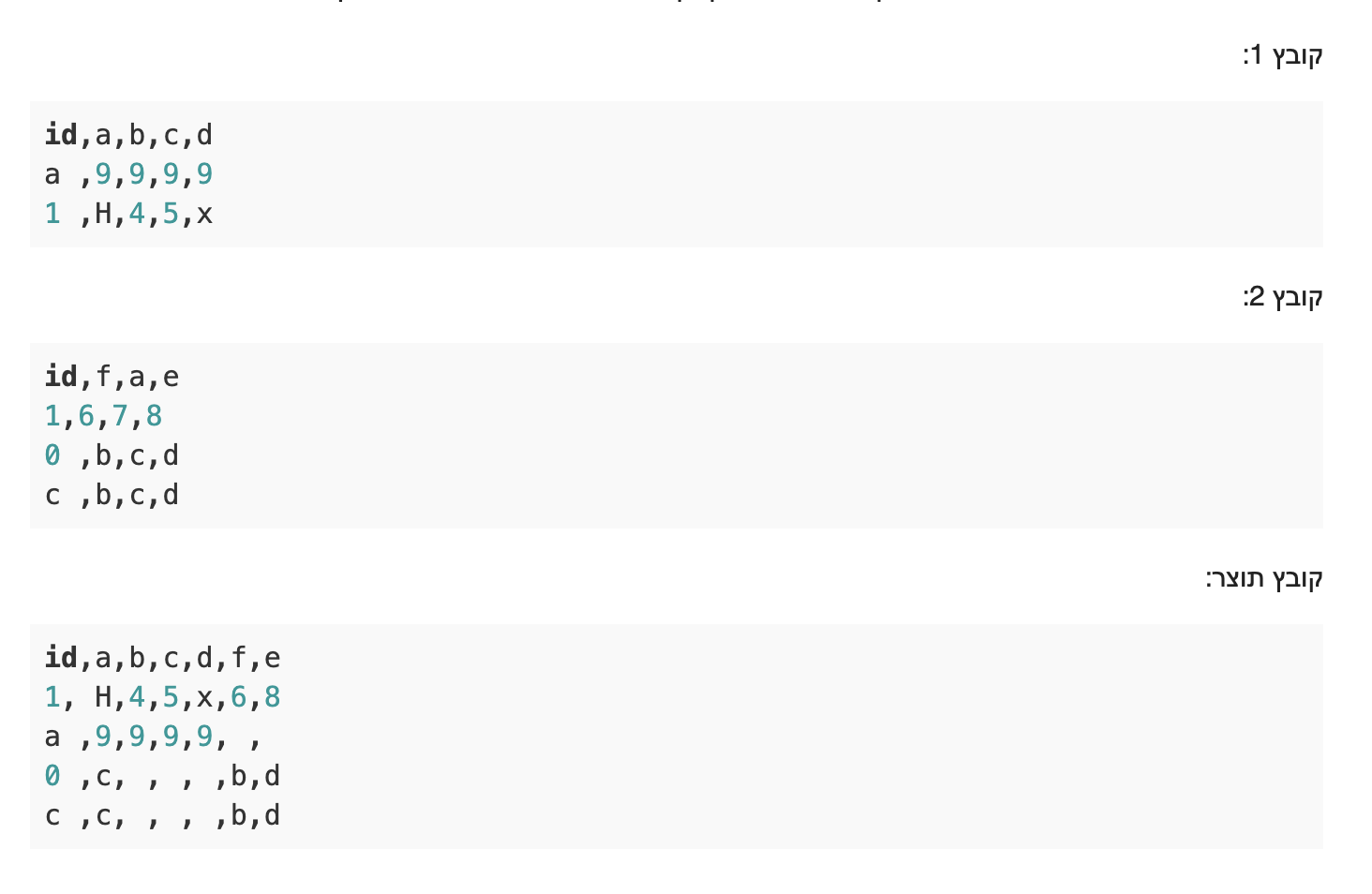
בקובץ 1 הid הראשון הוא a ואחריו 1
באחוד זה הפוך (תמונה מטה לנוחיותך)
מתנצלת על הקטנוניות, (ועל שאלת הקיטבג), רק מוודאת:
אם יש לי id שמופיע בשני הקבצים, אני יכולה להחליט לפי הסדר של איזה מהם אני הולכת?
לדוג׳:
id-ים של קובץ 1:
1
2
3
id-ים של קובץ 2:
5
1
4
id-ים של קובץ תוצר: (בחרתי לפי הקובץ הראשון)
1
2
3
5
4
אופציה ב׳:
5
1
4
2
3
לייק 1

כן, אין בעיה שתחליטי על איזה סדר ללכת במקרה כזה
לייק 1
היי ים!
שאלונת…נתקלתי בזה בתרגיל csv. מקווה שזה בסדר לשאול, כי זו שאלה כללית שאני לא בטוחה שיש לנו את הכלים לפתור כרגע (או בכלל?). אם זה קשור ספציפית לתרגיל אז תתעלם מהשאלה עד לאחר שעת ההגשה
שמתי לב שכשאני יוצרת תתי רשימות שכל התאים הינם רווח, אז כשאני רוצה לבצע השמה אני רואה שקורה דבר מוזר - ההשמה מתבצעת בכל תתי הרשימות מהסוג הזה באותו אינדקס…למרות שלא ביקשתי…
זה באג בפייתון?
לא הפרטים על למה זה קורה מופיעים במחברת 5 של שבוע 3
ממ אבל אני לא מצביעה לאותו זכרון (העתקתי בכל מעבר כמו שלמדנו)
בטוחה שהעתקת?
נסי לעקוב עם pythontutor
עריכה
נראה שהבנתי איפה היתה הבעיה…
תתי הרשימות המדוברים היו זהים והצביעו על אותו מקום בזכרון. אז למרות שביצעתי copy לרשימת האב, תתי הרשימות לא הועתקו.
אז 2 שאלות:
- לפעמים ערכים זהים יקבלו מקומות שונים ולפעמים לא (ללא קשר להשמה). יש דרך לזהות מתי כן ומתי לא?
- יש דרך לבצע copy כך שגם כל התתי יועתקו למקומות חדשים בזכרון?
כן אני בטוחה, כי הדפסתי את כל האידייז לפני ואחרי ליתר ביטחון וגם עקבתי יחד עם ה- tutor… מוזר לי…
אני מניח שאחרי שקראת את הקובץ את יצרת לולאה ועשית split לכל מחרוזת ברשימה והפכת לרשימה בפני עצמה.
אני אישית פשוט כשקראתי את הקובץ ושמרתי לרשימה יצרתי רשימה נוספת שהיא copy
ואז בלולאות כשפתחתי כל איבר לרשימה בפני עצמה, מיד אחרי עוד בתוך הלולאה אמרתי שהרשימה המועתקת במיקום הנוכחי הוא העתק של התת רשימה של המקורי
דבר נוסף, לא הבנתי איך לעבוד עם הtutor עם קבצים מהמחשב שלי. ניסיתי לתת לו כמובן את ה-path המלא
טוב אז אחרי שהגשנו את ה CSV רציתי לשאול מה אנשים עשו. הרגשתי שיצא לי קוד מסורבל (200 שורות!) ואני יודעת שהרבה אנשים עשו בפחות אז מעניין אותי גם מה הדרך שחשבתם עליה.
זה מה שאני עשיתי:
-
פחתי את הקבצים לקריאה ולכתיבה (הבנתי אחר כך שכדי לייעל עדיף להעתיק את מה שיש בהם לתוך משתנה)
-
יצירת כותרת:
א. לקחתי את השורה הראשונה בקובץ הראשון ואת השורה הראשונה בקובץ השני והפכתי אותן לרשימות.
ב. עברתי איבר איבר בשורה הראשונה בקובץ הראשון והשוותי אותו לכל האיברים בכותרת של הקובץ השני. אם מילה אחת הופיעה גם בקובץ השני, שמרתי את האינדקס שלה בקובץ השני.
ג. יצרתי רשימה חדשה. היא הכילה קודם כל את הכותרת של הקובץ הראשון. לאחר מכן לקחתי את הכותרת של הקובץ השני בצורת רשימה, ועברתי איבר איבר. אם האינדקס של האיבר הופיע ברשימה שיצרתי ב- ב’, כלומר צריך לדלג עליו, אז לא קרה כלום. אם הוא לא הופיע, הוספתי את האיבר לרשימה. בסוף הפכתי את הרשימה ל str וכתבתי אותה בקובץ.
איחוד הקבצים:
2. יצרתי רשימה של כל ה ID שנמצאים בקובץ השני
3. מצאתי באיזו עמודה בכל קובץ נמצא ה ID (על ידי הפעולה index)
4. עברתי על הקובץ הראשון שורה שורה. בכל שורה לקחתי את מה שנמצא בעמודת ה ID (לפי האינדס של ה ID) ובדקתי אם הוא נמצא ברשימה שיצרתי ב2.
אם הוא ברשימה:
5. מצאתי את השורה המתאימה בקובץ השני- עברתי על הקובץ השני שורה שורה, הפכתי כל שורה לרשימה ובדקתי אם במקום שהו אמור להיות ה ID נמצא ה ID שחיפשתי, אם כן החזרתי את השורה.
6. איחדתי את השורות בדומה למה שעשיתי בכותרת - יצרתי רשימה אליה הכנסתי את השורה הראשונה והוספתי לה את איברי השורה השנייה איבר איבר תוך כדי דילוג על המקומות שצריך לדלג עליהם.
אם הוא לא ברשימה:
7. הוספתי 0 לכל המוקמות בשורה עד סוף השורה- שנקבע לפי אורך הכותרת החדשה שיצרתי בהתחלה.
- ואז עברתי לקובץ השני וקראתי גם אותו שורה שורה והשוותי את הID של כל שורה לרשימה של ה ID שיש בקובץ הראשון.
- אם הID קים- התעלמתי כי כבר איחדתי שורות
- אם הID לא קיים, יצרתי רשימה חדשה.
- הפכתי גם את הכותרת של הקובץ השני הלא מאוחד לרשימה. עברתי על הכותרת של כל המסמך המאוחד איבר איבר. אם האיבר הופיע גם בכותרת של הקובץ השני- כלומר צריך לקחת את המידע מהקובץ השני:
- מצאתי את האינדקס של המידע הזה בקובץ השני (על ידי פעולת Index) והכנסתי את המידע משם לאינדקס הנוכחי.
- אם האיבר לא נמצא, כלומר אין את המידע הזה בקובץ השני, הכנסתי אפס.
בסוף כל יצירת שורה חדשה כתבתי את השורה החדשה למסמך.
אני מקווה שיצא מסביר מסודר וברור, ובכל מקרה גם אם לא יצאתי ברורה אני אשמח לשמוע מה אנשים אחרים עשו, גם אם בפחות פירוט. למרות שבטח עכשיו זה קצת יילך לאיבוד בשרשור הזה.
שלום לצוות,
לא הייתי מחובר “לתרגילי השלמה” היות והם נפתחו לתקופה קצרה בשבוע עמוס יחסית של זיכרון/ עצמאות, ולכן לא עשיתי אותם, יש אפשרות לפתוח אותם להגשה, או שלפחות לא יפסלו מקבלת תעודה?
לקח לי 88 שורות כולל פונקציה שכותבת את הקובץ וכולל מעט תיעוד והסברים.
מוזמנת להציץ:
# Gets two paths of files and merges them
def merge_files(file1_path, file2_path):
# Creates two lists of lists - the contents of the files
with open(file1_path, 'r') as file1:
file1_content = file1.read().split('\n')
with open(file2_path, 'r') as file2:
file2_content = file2.read().split('\n')
i = 0
while i < len(file1_content):
file1_content[i] = file1_content[i].split(',')
i += 1
i = 0
while i < len(file2_content):
file2_content[i] = file2_content[i].split(',')
i += 1
# Creates the merge of the title
i = 0
not_same = []
not_same_indexes = []
while i < len(file2_content[0]):
if file2_content[0][i] not in file1_content[0]:
not_same += file2_content[0][i]
not_same_indexes.append(i)
i += 1
new_file = file1_content.copy()
new_file[0].extend(not_same)
# Looking if there are same ids and if there are - adds them to the new file list
id_index_new_file = new_file[0].index("id")
id_index_file2 = file2_content[0].index("id")
file2_copy = file2_content.copy()
i = 1
while i < len(new_file):
j = 1
exist = False
while j < len(file2_content) and not exist:
if new_file[i][id_index_new_file] == file2_content[j][id_index_file2]:
exist = True
k = 0
while k < len(not_same_indexes):
new_file[i].append(file2_content[j][not_same_indexes[k]])
k += 1
file2_copy.pop(j)
j += 1
if not exist:
add = ['-'] * len(not_same)
new_file[i].extend(add)
i += 1
# Getting the indexes in the new file that appear in the file2
i = 0
indexes_list = []
while i < len(file2_copy[0]):
indexes_list.append(new_file[0].index(file2_copy[0][i]))
i += 1
# Adds the ids from file2 that aren't exist in file1 to the new file
k = 1
while k < len(file2_copy):
line = []
l = 0
while l < len(new_file[0]):
if l not in indexes_list:
line.append('-')
else:
line.append(file2_copy[k][indexes_list.index(l)])
l += 1
new_file.append(line)
k += 1
# Changing the list of the new file to a string in order to write it to the file
i = 0
print(new_file)
final = ""
while i < len(new_file):
line = ","
line = line.join(new_file[i])
final += line + '\n'
i += 1
final = final.strip()
# Writing it to the new file
with open("resources/merge.csv", 'w') as merge_file:
merge_file.write(final)
# Creates 2 files in order to check the merge function
def create_files():
with open("resources/file1.csv", 'w') as file1:
write1 = "a,b,c,d,id\n9,9,9,9,a\nH,4,5,x,1"
file1.write(write1)
with open("resources/file2.csv", 'w') as file2:
write2 = f"id,f,a,e\n1,6,7,8\n0,b,c,d\nc,b,c,d"
file2.write(write2)הבנתי, תודה על התשובה!
התהייה שלי אם ישנה דרך אלגנטית יותר.
כשיש כמה “דורות” של מחרוזות אז הקוד הופך לסופר לא אלגנטי.
קראתי קצת והגעתי ל-deepcopy. לא למדנו אבל יתכן וזה הפתרון. שיחקתי עם זה קצת וגם לפתרון הזה מצאתי מגבלות של דורות.
אז האמת שהדרך שאני בחרתי בה הייתה שיטה של אינדקסים, אולי קצת ארוך יותר אבל אפשר לי קצת יותר חופש.
אני עשיתי את איחוד הטבלה די דומה רק שבסוף התוצר שלי היה רשימה של רשימות, כאשר כל תת-רשימה היא שורה בטבלה והערכי הטבלה ריקים, מעבר ל-ID וכותרות.
זה בעצם אפשר לי לעבור אחר כך על כל תא בטבלה ולהתאים אותו לאינדקסים שלו. למשל, תא בשורה 2 (כאשר מתחילים מ-0) ובעמודה 3 (מתחילים מ-0) הוא למעשה טבלה[2][3], ממש כמו שמערך דו-מימדי עובד.
אבל יכול להיות שגם הדרך שלי לא הייתה יעילה מספיק
אני לא יודע מה זה אומר שזה 88 שורות כי הכנסת הכל לפונקציה אחת - אם היית מפרק את זה
לתתי פונקציות זה כנראה היה ארוך יותר
לא חושב שיש פה עניין של תחרות, וברור שכדי לייפות את הקוד אפשר לכתוב אותו בכמה פונקציות.
תוריד את התיעוד ותחלק לפונקציות ותקבל פחות או יותר אותו מספר שורות
אני לגמרי לא חושב שיש תחרות ובגלל זה רשמתי שאני לא חושב שזה משנה שזה 88 שורות
הדרך לפתרון היא החשובה
לייק 1